8. Mikado core algorithms¶
8.1. Picking transcripts: how to define loci and their members¶
The Mikado pick algorithm
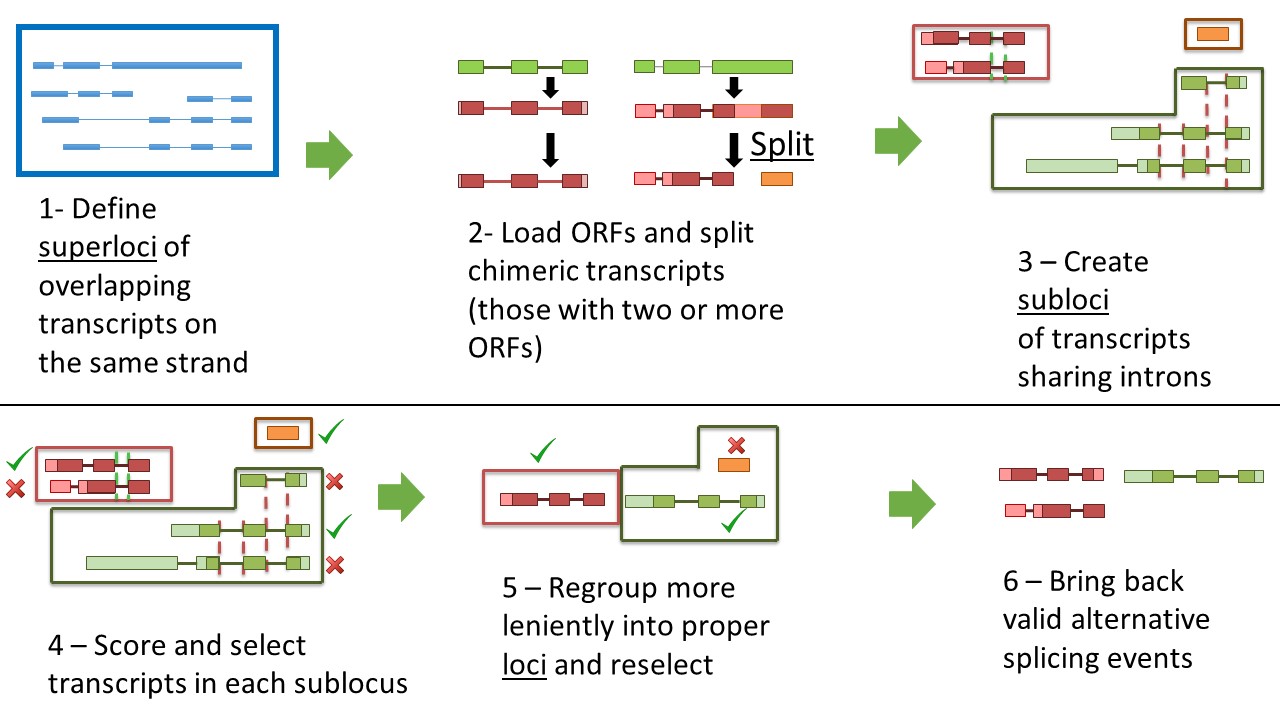
Schematic representation of how Mikado unbundles a complex locus into two separate genes.
Transcripts are scored and selected according to user-defined rules, based on many different features of the transcripts themselves (cDNA length, CDS length, UTR fraction, number of reliable junctions, etc.; please see the dedicated section on scoring for details on the scoring algorithm).
The detection and analysis of a locus proceeds as follows:
When the first transcript is detected, Mikado will create a superlocus - a container of transcripts sharing the same genomic location - and assign the transcript to it.
While traversing the genome, as long as any new transcript is within the maximum allowed flanking distance, it will be added to the superlocus.
When the last transcript is added, Mikado performs the following preliminary operations:
Integrate all the data from the database (including ORFs, reliable junctions in the region, and BLAST homology).
If a transcript is monoexonic, assign or reverse its strand if the ORF data supports the decision
If requested and the ORF data supports the operation, split chimeric transcripts - ie those that contain two or more non-overlapping ORFs on the same strand.
Split the superlocus into groups of transcripts that:
- share the same strand
- have at least 1bp overlap
Analyse each of these novel “stranded” superloci separately.
Create subloci, ie group transcripts so to minimize the probability of mistakenly merging multiple gene loci due to chimeras. These groups are defined as follows:
- if the transcripts are multiexonic, they must share at least one intron, inclusive of the borders
- if the transcripts are monoexonic, they must overlap by at least 1bp.
- Monoexonic and multiexonic transcripts cannot be part of the same sublocus.
Select the best transcript inside each sublocus:
- Score the transcripts (see the section on scoring)
- Select as winner the transcript with the highest score and assign it to a monosublocus
- Discard any transcript which is overlapping with it, according to the definitions in the point above
- Repeat the procedure from point 2 until no transcript remains in the sublocus
Monosubloci are gathered together into monosubloci holders, ie the seeds for the gene loci. Monosubloci holders have more lenient parameters to group transcripts, as the first phase should have already discarded most chimeras. Once a holder is created by a single monosublocus, any subsequent candidate monosublocus will be integrated only if the following conditions are satisfied:
if the candidate is monoexonic, its exon must overlap at least one exon of a transcript already present in the holder
if the candidate is multiexonic and the holder contains only monoexonic transcripts, apply the same criterion, ie check whether its exons overlap the exons of at least one of the transcripts already present
if the candidate is multiexonic and the holder contains multiexonic transcripts, check whether one of the following conditions is satisfied:
- at least one intron of the candidate overlaps with an intron of a transcript in the holder
- at least one intron of the candidate is completely contained within an exon of a transcript in the holder
- at least one intron of a transcript in the holder is completely contained within an exon of a transcript in the holder.
- the cDNA overlap and CDS overlap between the candidate and the transcript in the holder are over a specified threshold.
Optionally, it is possible to tell Mikado to use a simpler algorithm, and integrate together all transcripts that share exon space. Such a simpler algorithm risks, however, chaining together multiple loci - especially in small, compact genomes.
Once the holders are created, apply the same scoring and selection procedure of the sublocus selection step. The winning transcripts are assigned to the final loci. These are called the primary transcripts of the loci.
Once the loci are created, track back to the original transcripts of the superlocus:
discard any transcript overlapping more than one locus, as these are probably chimeras.
For those transcripts that are overlapping to a single locus, verify that they are valid alternative splicing events using the class code of the comparison against the primary transcript. Transcripts are re-scored dynamically when they are re-added in this fashion, to ensure their quality when compared with the primary transcript.
- For coding loci, transcripts will be added as alternative splicing events only if they are in the same frame as the primary transcript. New in version 1.5.
If there are transcripts that do not overlap any of the final loci, create a new superlocus with the missed transcripts and perform the scoring and selection again on them, until no transcript is unaccounted for.
After the alternative splicing events have been defined, Mikado can optionally “pad” them. See the padding section for details.
Finally detect and either tag or discard fragments inside the initial superlocus (irrespective of strand):
- Check whether the primary transcript of any locus meets the criteria to be defined as a fragment (by default, maximum ORF of 30AA and maximum 2 exons - any transcript exceeding either criterion will be considered as non-fragment by default)
- If so, verify whether they are near enough any valid locus to be considered as a fragment (in general, class codes which constitute the “Intronic”, “Fragmentary” and “No overlap” categories).
- If these conditions are met, tag the locus as a fragment. If requested, Mikado will just discard these transcripts (advised).
These steps help Mikado identify and solve fusions, detect correctly the gene loci, and define valid alternative splicing events.
8.2. Definition of retained introns¶
When gathering transcripts into loci, Mikado will try to identify and tag transcripts that contain retained intron events. For our purposes, a retained intron event is an exon which:
- is part of a coding transcript but is not completely coding itself.
- if it is an internal exon, it completely spans the putative retained intron.
- if it is a terminal exon, it must start within the exon of the putative retained intron, and terminate within the intron.
- if it constitutes a monoexonic transcript, at least one of the two ends must reside within the bordering exons.
In addition to this, a transcript might be tagged as having its CDS disrupted by the retained intron event if:
- the non-coding part of the exon is in the 3’UTR and it begins within the intron
- the exon is 3’ terminal, coding and it ends within the intron.
Warning
The definition of a retained intron is stricty context dependent, i.e. the same exon will be regarded as a “retained intron” if the transcript is gathered together with other transcripts, but as non-retained if it were in isolation. It is therefore normal and expected that the associated metrics and scores will change, for a given transcript, across the various clustering stages.
8.3. Identification and breaking of chimeric transcripts¶
When a transcript contains more than one ORF, Mikado will try to determine whether this is due to a retained intron event or a frameshift (in which case the two ORFs are presumed to be mangled forms of an original, correct ORF for a single protein) or whether instead this is due to the fragment being polycystronic (in a prokaryote) or chimeric (in a eukaryote). The latter case is relatively common due to technical artefacts during sequencing and assembling of RNASeq reads.
A chimeric transcript is defined by Mikado as a model with multiple ORFs, where:
- all the ORFs share the same strand
- all the ORFs are non-overlapping.
In these situations, Mikado can try to deal with the chimeras in five different ways, in decreasingly conservative fashion:
- nosplit: leave the transcript unchanged. The presence of multiple ORFs will affect the scoring.
- stringent: leave the transcript unchanged, unless the two ORFs both have hits in the protein database and none of the hits is in common.
- lenient: leave the transcript unchanged, unless either the two ORFs both have hits in the protein database, none of which is in common, or both have no hits in the protein database.
- permissive: presume the transcript is a chimera, and split it, unless two ORFs share a hit in the protein database.
- split: presume that every transcript with more than one ORF is incorrect, and split them.
If any BLAST hit spans the two ORFs, then the model will be considered as a non-chimera because there is evidence that the transcript constitutes a single unit. The only case when this information will be disregarded is during the execution of the split mode.
These modes can be controlled directly from the pick command line, or during the initial configuration stage.
8.4. Transcript measurements and scoring¶
In order to determine the best transcript for each locus, Mikado measures each available candidate according to various different metrics and assigning a specific score for each of those. Similarly to RAMPART [Rampart], Mikado will assign a score to each transcript for each metric by assessing it relatively to the other transcripts in the locus. The particular feature rescaling equation used for a given metric depends on the type of feature it represents:
- metrics where higher values represent better transcript assemblies (“maximum”).
- metrics where lower values represent better transcript assemblies (“minimum”)
- metrics where values closer to a defined value represent better assemblies (“target”)
To allow for this tripartite scoring system with disparate input values, we have to employ rescaling equations so that each metric for each transcript will be assigned a score between 0 and 1. Optionally, each metric might be assigned a greater weight so that its maximum possible value will be greater or smaller than 1. Formally, let metric \(m\) be one of the available metrics \(M\), \(t\) a transcript in locus \(L\), \(w_{m}\) the weight assigned to metric \(m\), and \(r_{mt}\) the raw value of metric \(m\) for \(t\). Then, the score to metric \(m\) for transcript \(t\), \(s_{mt}\), will be derived using one of the following three different rescaling equations:
- If higher values are best:
- \(s_{mt} = w_{m} * (\frac{r_{mt} - min(r_m)}{max(r_m)-min(r_m)})\)
- If lower values are best:
- \(s_{mt} = w_{m} * (1 - \frac{r_{mt} - min(r_m)}{max(r_m)-min(r_m)})\)
- If values closer to a target \(v_{m}\) are best:
- \(s_{mt} = w_{m} * (1 - \frac{|r_{mt} - v_{m}|}{max(|r_{m} - v_{m}|)})\)
- Finally, the scores for each metric will be summed up to produce a final score for the transcript:
- \(s_{t} = \sum_{m \forall m \in M} s_{mt}\).
Not all the available metrics will be necessarily used for scoring; the choice of which to employ and how to score and weight each of them is left to the experimenter, although Mikado provides some pre-configured scoring files. Values that are guaranteed to be between 0 and 1 (e.g. a percentage value) can be used directly as scores, by setting the use_raw parameter as true for them (see below).
Important
The scoring algorithm is dependent on the other transcripts in the locus, so each score should not be taken as an absolute measure of the reliability of a transcript, but rather as a measure of its relative goodness compared with the alternatives. Shifting a transcript from one locus to another can have dramatic effects on the scoring of a transcript, even while the underlying metric values remain unchanged. This is why the score assigned to each transcript changes throughout the Mikado run, as transcripts are moved to subloci, monoloci and finally loci.
8.5. Scoring files¶
Mikado employs user-defined configuration files to define the desirable features in genes. These files are in either YAML or JSON format (default YAML) and are composed of four sections:
- a requirements section, specifying the minimum requirements that a transcript must satisfy to be considered as valid. Any transcript failing these requirements will be scored at 0 and purged.
- a not_fragmentary section, specifying the minimum requirements that the primary transcript of a locus has to satisfy in order for the locus not to be considered as a putative fragment.
- an as_requirements section, which specifies the minimum requirements for transcripts for them to be considered as possible valid alternative splicing events.
- a scoring section, specifying which features Mikado should look for in transcripts, and how each of them will be weighted.
Conditions are specified using a strict set of available operators and the values they have to consider.
Important
Although at the moment Mikado does not offer any method to establish machine-learning based scoring configurations, it is a topic we plan to investigate in the future. Mikado already supports Random Forest Regressors as scorers through Scikit-learn, but we have yet to devise a proper way to create such regressors.
We provide a guide on how to write your own scoring files in a separate tutorial.
8.5.1. Operators¶
Mikado allows the following operators to express a relationship inside the scoring files:
- eq: equal to (\(=\)). Valid for comparisons with numbers, boolean values, and strings.
- ne: different from (\(\neq\)). Valid for comparisons with numbers, boolean values, and strings.
- lt: less than (\(<\)). Valid for comparisons with numbers.
- gt: greater than (\(>\)). Valid for comparisons with numbers.
- le: less or equal than (\(\le\)). Valid for comparisons with numbers.
- ge: greater or equal than (\(\ge\)). Valid for comparisons with numbers.
- in: member of (\(\in\)). Valid for comparisons with arrays or sets.
- not in: not member of (\(\notin\)). Valid for comparisons with arrays or sets.
- within: value comprised in the range of the two values, inclusive.
- not within: value not comprised in the range of the two values, inclusive.
Mikado will fail if an operator not present on this list is specified, or if the operator is assigned to compare against the wrong data type (eg. eq with an array).
8.5.2. The “requirements”, “as_requirements” and “not_fragmentary” sections¶
These sections specifies the minimum requirements for a transcript at various stages.
- A transcript failing to pass the requirements check will be discarded outright (if “purge” is selected) or given a score of 0 otherwise.
- If a transcript has not been selected as the primary transcript of a locus, it has to pass the as_requirements check to be considered as a valid alternative splicing event.
- Finally, after loci have been defined, the primary transcripts of loci that do not pass the not_fragmentary section mark their loci to be compared against neighbouring loci which have passed this same check.
It is strongly advised to use lenient parameters in the requirements section, as failing to do so might result in discarding whole loci. Typically, transcripts filtered at this step should be obvious fragments, eg monoexonic transcripts produced by RNA-Seq with a total length lower than the library fragment length. This section is composed by two parts:
parameters: a list of the metrics to be considered. Each metric can be considered multiple times, by suffixing it with a “.<id>” construct (eg cdna_length.*mono* vs. cdna_length.*multi* to distinguish two uses of the cdna_length metric - once for monoexonic and once for multiexonic transcripts). Any parameter which is not a valid metric name, after removal of the suffix, will cause an error. Parameters have to specify the following:
- a value that the metric has to be compared against
- an operator that specifies the target operation. See the operators section.
expression: a string array that will be compiled into a valid boolean expression. All the metrics present in the expression string must be present in the parameters section. If an unrecognized metric is present, Mikado will crash immediately, complaining that the scoring file is invalid. Apart from brackets, Mikado accepts only the following boolean operators to chain the metrics:
- and
- or
- not
- xor
Hint
if no expression is specified, Mikado will construct one by chaining all the provided parameters with and and operator. Most of the time, this would result in an unexpected behaviour - ie Mikado assigning a score of 0 to most transcripts. It is strongly advised to explicitly provide a valid expression.
As an example, the following snippet replicates a typical requirements section found in a scoring file:
requirements:
expression: [((exon_num.multi and cdna_length.multi and max_intron_length and min_intron_length), or,
(exon_num.mono and cdna_length.mono))]
parameters:
cdna_length.mono: {operator: gt, value: 50}
cdna_length.multi: {operator: ge, value: 100}
exon_num.mono: {operator: eq, value: 1}
exon_num.multi: {operator: gt, value: 1}
max_intron_length: {operator: le, value: 20000}
min_intron_length: {operator: ge, value: 5}
In the parameters section, we ask for the following:
- exon_num.mono: monoexonic transcripts must have one exon (“eq”)
- exon_num.multi: multiexonic transcripts must have more than one exon (“gt”)
- cdna_length.mono: monoexonic transcripts must have a length greater than 50 bps (the “.mono” suffix is arbitrary, as long as it is unique for all calls of cdna_length)
- cdna_length.multi: multiexonic transcripts must have a length greater than or equal to 100 bps (the “.multi” suffix is arbitrary, as long as it is unique for all calls of cdna_length)
- max_intron_length: multiexonic transcripts should not have any intron longer than 200,000 bps.
- min_intron_length: multiexonic transcripts should not have any intron smaller than 5 bps.
The expression field will be compiled into the following expression:
(exon_num > 1 and cdna_length >= 100 and max_intron_length <= 200000 and min_intron_length >= 5) or (exon_num == 1 and cdna_length > 50)
Any transcript for which the expression evaluates to false will be assigned a score of 0 outright and discarded, unless the user has chosen to disable the purging of such transcripts.
8.5.3. The scoring section¶
This section specifies which metrics will be used by Mikado to score the transcripts. Each metric to be used is specified as a subsection of the configuration, and will have the following attributes:
rescaling: the only compulsory attribute. It specifies the kind of scoring that will be applied to the metric, and it has to be one of “max”, “min”, or “target”. See the explanation on the scoring algorithm for details.
value: compulsory if the chosen rescaling algorithm is “target”. This should be either a number or a boolean value.
multiplier: the weight assigned to the metric in terms of scoring. This parameter is optional; if absent, as it is in the majority of cases, Mikado will consider the multiplier to equal to 1. This is the \(w_{m}\) element in the equations above.
filter: It is possible to specify a filter which the metric has to fulfill to be considered for scoring, eg, “cdna_length >= 200”. If the transcript fails to pass this filter, the score for this metric only will be set to 0. A “filter” subsection has to specify the following:
- operator: the operator to apply for the boolean expression. See the relative section.
- value: value that will be used to assess the metric.
Hint
the purpose of the filter section is to allow for fine-tuning of the scoring mechanism; ie it allows to penalise transcripts with undesirable qualities (eg a possible retained intron) without discarding them outright. As such, it is a less harsh version of the requirements section and it is the preferred way of specifying which transcript features Mikado should be wary of.
For example, this is a snippet of a scoring section:
scoring:
blast_score: {rescaling: max}
cds_not_maximal: {rescaling: min}
combined_cds_fraction: {rescaling: target, value: 0.8, multiplier: 2}
five_utr_length:
filter: {operator: le, value: 2500}
rescaling: target
value: 100
end_distance_from_junction:
filter: {operator: lt, value: 55}
rescaling: min
non_verified_introns_num:
rescaling: max
multiplier: -10
filter:
operator: gt
value: 1
metric: exons_num
Using this snippet as a guide, Mikado will score transcripts in each locus as follows:
- Assign a full score (one point, as no multiplier is specified) to transcripts which have the greatest blast_score
- Assign a full score (one point, as no multiplier is specified) to transcripts which have the lowest amount of CDS bases in secondary ORFs (cds_not_maximal)
- Assign a full score (two points, as a multiplier of 2 is specified) to transcripts that have a total amount of CDS bps approximating 80% of the transcript cDNA length (combined_cds_fraction)
- Assign a full score (one point, as no multiplier is specified) to transcripts that have a 5’ UTR whose length is nearest to 100 bps (five_utr_length); if the 5’ UTR is longer than 2,500 bps, this score will be 0 (see the filter section)
- Assign a full score (one point, as no multiplier is specified) to transcripts which have the lowest distance between the CDS end and the most downstream exon-exon junction (end_distance_from_junction). If such a distance is greater than 55 bps, assign a score of 0, as it is a probable target for NMD (see the filter section).
- Assign a maximum penalty (minus 10 points, as a negative multiplier is specified) to the transcript with the highest number of non-verified introns in the locus.
- Again, we are using a “filter” section to define which transcripts will be exempted from this scoring (in this case, a penalty)
- However, please note that we are using the keyword metric in this section. This tells Mikado to check a different metric for evaluating the filter. Nominally, in this case we are excluding from the penalty any monoexonic transcript. This makes sense as a monoexonic transcript will never have an intron to be confirmed to start with.
Note
The possibility of using different metrics for the “filter” section is present from Mikado 1.3 onwards.
8.6. Metrics¶
These are all the metrics available to quantify transcripts. The documentation for this section has been generated using the metrics utility.
Metrics belong to one of the following categories:
- Descriptive: these metrics merely provide a description of the transcript (eg its ID) and are not used for scoring.
- cDNA: these metrics refer to basic features of any transcript such as its number of exons, its cDNA length, etc.
- Intron: these metrics refer to features related to the number of introns and their lengths.
- CDS: these metrics refer to features related to the CDS assigned to the transcript.
- UTR: these metrics refer to features related to the UTR of the transcript. In the case in which a transcript has been assigned multiple ORFs, unless otherwise stated the UTR metrics will be derived only considering the selected ORF, not the combination of all of them.
- Locus: these metrics refer to features of the transcript in relationship to all other transcripts in its locus, eg how many of the introns present in the locus are present in the transcript. These metrics are calculated by Mikado during the picking phase, and as such their value can vary during the different stages as the transcripts are shifted to different groups.
- External: these metrics are derived from accessory data that is recovered for the transcript during the run time. Examples include data regarding the number of introns confirmed by external programs such as PortCullis, or the BLAST score of the best hits.
Hint
Starting from version 1 beta8, Mikado allows to use externally defined metrics for the transcripts. These can be accessed using the keyword “external.<name of the metrics>” within the configuration file. See the relevant section for details.
Important
Starting from Mikado 1 beta 8, it is possible to use metrics with values between 0 and 1 directly as scores, without rescaling. This feature is available only for metrics whose values naturally lie between 0 and 1, or that are boolean in nature.
| Metric name | Description | Category | Data type | Usable raw |
|---|---|---|---|---|
| tid | ID of the transcript - cannot be an undefined value. Alias of id. | Descriptive | str | False |
| parent | Name of the parent feature of the transcript. | Descriptive | str | False |
| score | Numerical value which summarizes the reliability of the transcript. | Descriptive | str | False |
| external_scores | SPECIAL this Namespace contains all the information regarding external scores for the transcript. If an absent property is not defined in the Namespace, Mikado will set a default value of 0 into the Namespace and return it. | External | Namespace | True |
| best_bits | Metric that returns the best BitS associated with the transcript. | External | float | False |
| blast_identity | This metric will return the alignment identity for the best BLAST hit according to the evalue. If no BLAST hits are available for the sequence, it will return 0. :return: :return: | External | float | True |
| blast_query_coverage | This metric will return the query coverage for the best BLAST hit according to the evalue. If no BLAST hits are available for the sequence, it will return 0. :return: | External | float | True |
| blast_score | Interchangeable alias for testing different blast-related scores. Current: best bit score. | External | float | False |
| blast_target_coverage | This metric will return the target coverage for the best BLAST hit according to the evalue. If no BLAST hits are available for the sequence, it will return 0. :return: :return: | External | float | True |
| canonical_intron_proportion | This metric returns the proportion of canonical introns of the transcript on its total number of introns. | Intron | float | True |
| cdna_length | This property returns the length of the transcript. | cDNA | int | False |
| cds_not_maximal | This property returns the length of the CDS excluded from the selected ORF. | CDS | int | False |
| cds_not_maximal_fraction | This property returns the fraction of bases not in the selected ORF compared to the total number of CDS bases in the cDNA. | CDS | float | True |
| combined_cds_fraction | This property return the percentage of the CDS part of the transcript vs. the cDNA length | CDS | float | True |
| combined_cds_intron_fraction | This property returns the fraction of CDS introns of the transcript vs. the total number of CDS introns in the Locus. If the transcript is by itself, it returns 1. | Locus | True | |
| combined_cds_length | This property return the length of the CDS part of the transcript. | CDS | int | False |
| combined_cds_locus_fraction | This metric returns the fraction of CDS bases of the transcript vs. the total of CDS bases in the locus. | Locus | float | True |
| combined_cds_num | This property returns the number of non-overlapping CDS segments in the transcript. | CDS | int | False |
| combined_cds_num_fraction | This property returns the fraction of non-overlapping CDS segments in the transcript vs. the total number of exons | CDS | float | True |
| combined_utr_fraction | This property returns the fraction of the cDNA which is not coding according to any ORF. Complement of combined_cds_fraction | UTR | float | True |
| combined_utr_length | This property return the length of the UTR part of the transcript. | UTR | int | False |
| end_distance_from_junction | This metric returns the cDNA distance between the stop codon and the last junction in the transcript. In many eukaryotes, this distance cannot exceed 50-55 bps otherwise the transcript becomes a target of NMD. If the transcript is not coding or there is no junction downstream of the stop codon, the metric returns 0. This metric considers the combined CDS end. | CDS | int | False |
| end_distance_from_tes | This property returns the distance of the end of the combined CDS from the transcript end site. If no CDS is defined, it defaults to 0. | CDS | int | False |
| exon_fraction | This property returns the fraction of exons of the transcript which are contained in the sublocus. If the transcript is by itself, it returns 1. Set from outside. | Locus | float | True |
| exon_num | This property returns the number of exons of the transcript. | cDNA | int | False |
| five_utr_length | Returns the length of the 5’ UTR of the selected ORF. | UTR | False | |
| five_utr_num | This property returns the number of 5’ UTR segments for the selected ORF. | UTR | int | False |
| five_utr_num_complete | This property returns the number of 5’ UTR segments for the selected ORF, considering only those which are complete exons. | UTR | int | False |
| has_start_codon | Boolean. True if the selected ORF has a start codon. | CDS | bool | False |
| has_stop_codon | Boolean. True if the selected ORF has a stop codon. | CDS | bool | False |
| highest_cds_exon_number | This property returns the maximum number of CDS segments among the ORFs; this number can refer to an ORF DIFFERENT from the maximal ORF. | CDS | int | False |
| highest_cds_exons_num | Returns the number of CDS segments in the selected ORF (irrespective of the number of exons involved) | CDS | int | False |
| intron_fraction | This property returns the fraction of introns of the transcript vs. the total number of introns in the Locus. If the transcript is by itself, it returns 1. Set from outside. | Locus | float | True |
| is_complete | Boolean. True if the selected ORF has both start and end. | CDS | bool | False |
| max_exon_length | This metric will return the length of the biggest exon in the transcript. | cDNA | int | False |
| max_intron_length | This property returns the greatest intron length for the transcript. | Intron | int | False |
| min_exon_length | This metric will return the length of the biggest exon in the transcript. | False | ||
| min_intron_length | This property returns the smallest intron length for the transcript. | Intron | int | False |
| non_verified_introns_num | This metric returns the number of introns of the transcript which are not validated by external data. | External | int | False |
| num_introns_greater_than_max | This metric returns the number of introns greater than the maximum acceptable intron size indicated in the constructor. | Intron | int | False |
| num_introns_smaller_than_min | This metric returns the number of introns smaller than the mininum acceptable intron size indicated in the constructor. | Intron | int | False |
| number_internal_orfs | This property returns the number of ORFs inside a transcript. | CDS | int | False |
| only_non_canonical_splicing | This metric will return True if the canonical_number is 0 | Intron | bool | False |
| proportion_verified_introns | This metric returns, as a fraction, how many of the transcript introns are validated by external data. Monoexonic transcripts are set to 1. | External | float | True |
| proportion_verified_introns_inlocus | This metric returns, as a fraction, how many of the verified introns inside the Locus are contained inside the transcript. | Locus | float | True |
| retained_fraction | This property returns the fraction of the cDNA which is contained in retained introns. | Locus | float | True |
| retained_intron_num | This property records the number of introns in the transcripts which are marked as being retained. See the corresponding method in the sublocus class. | Locus | int | False |
| selected_cds_exons_fraction | Returns the fraction of CDS segments in the selected ORF (irrespective of the number of exons involved) | CDS | float | True |
| selected_cds_fraction | This property calculates the fraction of the selected CDS vs. the cDNA length. | CDS | float | True |
| selected_cds_intron_fraction | This property returns the fraction of CDS introns of the selected ORF of the transcript vs. the total number of CDS introns in the Locus (considering only the selected ORF). If the transcript is by itself, it should return 1. | CDS | float | True |
| selected_cds_length | This property calculates the length of the CDS selected as best inside the cDNA. | CDS | int | False |
| selected_cds_locus_fraction | This metric returns the fraction of CDS bases of the transcript vs. the total of CDS bases in the locus. | Locus | float | True |
| selected_cds_num | This property calculates the number of CDS exons for the selected ORF | CDS | int | False |
| selected_cds_number_fraction | This property returns the proportion of best possible CDS segments vs. the number of exons. See selected_cds_number. | CDS | float | False |
| selected_end_distance_from_junction | This metric returns the distance between the stop codon and the last junction of the transcript. In many eukaryotes, this distance cannot exceed 50-55 bps, otherwise the transcript becomes a target of NMD. If the transcript is not coding or there is no junction downstream of the stop codon, the metric returns 0. | CDS | int | False |
| selected_end_distance_from_tes | This property returns the distance of the end of the best CDS from the transcript end site. If no CDS is defined, it defaults to 0. | CDS | int | False |
| selected_start_distance_from_tss | This property returns the distance of the start of the best CDS from the transcript start site. If no CDS is defined, it defaults to 0. | CDS | int | False |
| snowy_blast_score | Metric that indicates how good a hit is compared to the competition, in terms of BLAST similarities. As in SnowyOwl, the score for each hit is calculated by taking the coverage of the target and dividing it by (2 * len(self.blast_hits)). IMPORTANT: when splitting transcripts by ORF, a blast hit is added to the new transcript only if it is contained within the new transcript. This WILL screw up a bit the homology score. | External | float | False |
| source_score | This metric returns a score that is assigned to the transcript in virtue of its origin. | External | int | False |
| start_distance_from_tss | This property returns the distance of the start of the combined CDS from the transcript start site. If no CDS is defined, it defaults to 0. | CDS | int | False |
| suspicious_splicing | This metric will return True if the transcript either has canonical introns on both strands (probably a chimeric artifact between two neighbouring loci, or if it has no canonical splicing event but it would if it were assigned to the opposite strand (probably a strand misassignment on the part of the assembler/predictor). | Intron | bool | False |
| three_utr_length | Returns the length of the 5’ UTR of the selected ORF. | int | False | |
| three_utr_num | This property returns the number of 3’ UTR segments (referred to the selected ORF). | UTR | int | False |
| three_utr_num_complete | This property returns the number of 3’ UTR segments for the selected ORF, considering only those which are complete exons. | UTR | int | False |
| utr_fraction | This property calculates the length of the UTR of the selected ORF vs. the cDNA length. | UTR | float | True |
| utr_length | Returns the sum of the 5’+3’ UTR lengths | UTR | int | False |
| utr_num | Returns the number of UTR segments (referred to the selected ORF). | UTR | int | False |
| utr_num_complete | Returns the number of UTR segments which are complete exons (referred to the selected ORF). | UTR | int | False |
| verified_introns_num | This metric returns the number of introns of the transcript which are validated by external data. | External | int | False |
8.7. External metrics¶
Starting from version 1 beta 8, Mikado allows to load external metrics into the database, to be used for evaluating transcripts. Metrics of this kind must have a value comprised between 0 and 1. The file can be provided either by specifying it in the coonfiguration file, under “serialise/files/external_scores”, or on the command line with the “–external-scores” parameters to mikado serialise. The external scores file should have the following format:
| TID | Metric_one | Metric_two | … | Metric_N |
|---|---|---|---|---|
| Transcript_one | value | value | value | |
| Transcript_two | value | value | value | |
| … | … | … | … | |
| Transcript_N | value | value | value |
Please note the following:
- the header is mandatory.
- the metric names at the head of the table should not contain any space or spcecial characters, apart from the underscore (_)
- the header provides the name of the metric as will be seen by Mikado. As such, it is advised to choose sensible and informative names (e.g. “fraction_covered”) rather than uninformative ones (e.g. the “metric_one” from above)
- Column names must be unique.
- The transcript names present in the first column must be present in the FASTA file.
- The table should be tab-separated.
- Values can be of any numerical or boolean type. However, only values that are determined at serialisation to be comprised within 0 and 1 (inclusive) can be used as raw values.
A proper way of generating and using external scores would, therefore, be the following:
- Run Mikado prepare on the input dataset.
- Run all necessary supplementary analyses (ORF calling and/or homology analysis through DIAMOND or BLAST).
- Run supplementary analyses to assess the transcripts, e.g. expression analysis. Normalise results so that they can be expressed with values between 0 and 1.
- Please note that boolean results (e.g. presence or absence) can be expressed with 0 and 1 intead of “False” and “True”. Customarily, in Python 0 stands for False and 1 for True, but you can choose to switch the order if you so desire.
- Aggregate all results in a text table, like the one above, tab separated.
- Call mikado serialise, specifying the location of this table either through the configuration file or on the command line invocation.
Given the open ended nature of the external scores, the Daijin pipeline currently does not offer any system to generate these scores. This might change in the future.
8.7.1. Adding external scores to the scoring file¶
Once the external metrics have been properly loaded, it is necessary to tell Mikado how to use them. This requires modifying the scoring file itself. The header that we used in the table above does provide the names of the metrics as they will be seen by Mikado.
Let us say that we have performed an expression analysis on our transcripts, and we have created and loaded the following three metrics:
- “fraction_covered”, ie the percentage of the transcript covered by at least X reads (where X is decided by the experimenter)
- “samples_expressed”, ie the percentage of samples where the transcript was expressed over a certain threshold (e.g. 1 TPM)
- “has_coverage_gaps”, ie a boolean metrics that indicates whether there are windows within the transcript that lowly or not at all covered (e.g. a 100bp stretch with no coverage between two highly covered regions, indicating a possilble intron retention or chimera). For this example, a value of “0” indicates that there no coverage gaps (ie. it is False that there are gaps), “1” otherwise (it is True that there are coverage gaps).
We can now use these metrics as normal, by invoking them as “external.” followed by the name of the metrics: e.g., “external.fraction_covered”. So for example, if we wished to prioritise transcripts that are expressed in the highest number of samples and are completely covered by RNASeq data upon reads realignment, under “scoring”, we can add the following:
scoring:
# [ ... other metrics ... ]
- external.samples_expressed: {rescaling: max}
- external.fraction_covered: {rescaling: max}
And if we wanted to consider any primary transcript with coverage gaps as a potential fragment, under the “fragmentary” section we could do so:
not_fragmentary:
expression:
# other metrics ..
- and (external.has_coverage_gaps)
# Finished expression
parameters:
# other metrics ...
external.has_coverage_gaps: {operator: eq, value: 0} # Please note, again, that here "0" means "no coverage gaps detected".
# other metrics ...
As external metrics allow Mikado to accept any arbitrary metric for each transcript, they allow the program to assess transcripts in any way the experimenter desires. However, currently we do not provide any way of automating the process.
Note
also for external metrics, it is necessary to add a suffix to them if they are invoked more than once in an expression (see the tutorial). An invocation of e.g. “external.samples_expressed.mono” and “external.samples_expressed.multi”, to distinguish between monoexonic and multiexonic transcripts, would be perfectly valid and actually required by Mikado. Notice the double use of the dot (“.”) as separator. Its usage as such is the reason that it cannot be present in the name of the metric itself (so, for example, “has.coverage.gaps” would be an invalid metric name).
8.8. Padding transcripts¶
Mikado has the ability of padding transcripts in a locus, so to uniform their starts and stops, and to infer the presence of missing exons from neighbouring data. The procedure is similar to the one employed by PASA and functions as follows:
- A transcript can function as template for a candidate if:
- the candidate’s terminal exon falls within an exon of the template
- the extension would enlarge the candidate by at most “ts_distance” basepairs (not including introns), default 1000 bps
- the extension would add at most “ts_max_splices” splice sites to the candidate, default 2.
- A graph of possible extensions is built for both the 5’ end and the 3’ end of the locus. Transcripts are then divided in extension groups, starting with the outmost (ie the potential template for the group). Links that would cause chains (e.g. A can act as template for B and B can act as template for C, but A cannot act as template for C) are broken.
- Create a copy of the transcripts in the locus, for backtracking.
- Start expanding each transcript:
- Create a copy of the transcript for backtracking
- Calculate whether the 5’ terminal exon should be enlarged:
- if the transcript exon terminally overlaps a template exon, enlarge it until the end of the template
- If the template transcript has multiple exons upstream of the expanded exon, add those to the transcript.
- Calculate the number of bases that have been added upstream to the cDNA of the transcript
- Calculate whether the 3’ terminal exon should be enlarged:
- if the transcript exon terminally overlaps a template exon, enlarge it until the end of the template
- If the template transcript has multiple exons downstream of the expanded exon, add those to the transcript.
- Calculate the number of bases that have been added downstream to the cDNA of the transcript
- If the transcript is coding:
- Calculate the new putative CDS positions in the transcript, using the memoized amount of added basepairs downstream and upstream
- Calculate the new CDS, keeping the same frame as the original transcript. If the transcript is incomplete, this might lead to find the proper start and stop codons
- If we find an in-frame stop codon, the expansion would lead to an invalid transcript. Backtrack.
- Recalculate metrics and scores.
- Check whether we have made any transcript an invalid alternative splicing event; possible common causes include:
- Having created a retained intron
- Having expanded the number or size of the UTR so that the transcripts are no longer viable
- If any of the non-viable transcripts is either the primary transcript or one of the templates, remove the current templates from the locus and restart the analysis.
- Discard all the non-viable transcripts that are neither the primary nor templates.
When calculating the new ORF, Mikado will use the same codon table selected for the serialisation step.
This option is normally activated, with the parameters:
- Default maximum splice sites that can be crossed: 2
- Default maximum basepair distance: 1000
Note
please consider that the parameters above refer to the expansion on both sides of the transcript. So the parameters above allow transcripts to be expanded by up to 2000 bps, ie 1000 in both directions.
This option has been written for using Mikado in conjunction with ab initio predictions, but it can be used fruitfully also with transcript assemblies.
Warning
Please note that some of the metrics might become invalid after the padding. In particular, BLASTX results will be invalid as the query sequence will have changed.
The options related to padding can be found under the pick section in the configuration file.
8.9. Technical details¶
Most of the selection (ie “pick”) stage of the pipeline relies on the implementation of the objects in the loci submodule. In particular, the library defines an abstract class, “Abstractlocus”, which requires all its children to implement a version of the “is_intersecting” method. Each implementation of the method is specific to the stage. So the superlocus class will require in the “is_intersecting” method only overlap between the transcripts, optionally with a flanking and optionally restricting the groups to transcripts that share the same strand. The sublocus class will implement a different algorithm, and so on. The scoring is effectuated by first asking to recalculate the metrics (.calculate_metrics) and subsequently to calculate the scores (.calculate_scores). Mikado will try to cache and avoid recalculation of metrics and scores as much as possible, to make the program faster.
Metrics are an extension of the property construct in Python3. Compared to normal properties, they are distinguished only by three optional descriptive attributes: category, usable_raw, and rtype. The main reason to subclass property is to allow Mikado to be self-aware of which properties will be used for scoring transcripts, and which will not. So, for example, in the following snippet from the Transcript class definition:
@property
def combined_cds(self):
"""This is a list which contains all the non-overlapping CDS
segments inside the cDNA. The list comprises the segments
as duples (start,end)."""
return self.__combined_cds
@combined_cds.setter
def combined_cds(self, combined):
"""
Setter for combined_cds. It performs some basic checks,
e.g. that all the members of the list are integer duplexes.
:param combined: list
:type combined: list[(int,int)]
"""
if ((not isinstance(combined, list)) or
any(self.__wrong_combined_entry(comb) for comb in combined)):
raise TypeError("Invalid value for combined CDS: {0}".format(combined))
@Metric
def combined_cds_length(self):
"""This property return the length of the CDS part of the transcript."""
c_length = sum([c[1] - c[0] + 1 for c in self.combined_cds])
if len(self.combined_cds) > 0:
assert c_length > 0
return c_length
combined_cds_length.category = "CDS"
@Metric
def combined_cds_num(self):
"""This property returns the number of non-overlapping CDS segments
in the transcript."""
return len(self.combined_cds)
combined_cds_num.category = "CDS"
@Metric
def has_start_codon(self):
"""Boolean. True if the selected ORF has a start codon.
:rtype: bool"""
return self.__has_start_codon
@has_start_codon.setter
def has_start_codon(self, value):
"""Setter. Checks that the argument is boolean.
:param value: boolean flag
:type value: bool
"""
if value not in (None, False, True):
raise TypeError(
"Invalid value for has_start_codon: {0}".format(type(value)))
self.__has_start_codon = value
has_start_codon.category = "CDS"
Mikado will recognize that “derived_children” is a normal property, while “combined_cds_length”, “combined_cds_num” and “has_start_codon” are Metrics (and as such, we assign them a “category” - by default, that attribute will be None.). Please note that Metrics behave and are coded like normal properties in any other regard - including docstrings and setters/deleters.
The requirements expression is evaluated using eval.
Warning
While we took pains to ensure that the expression is properly sanitised and inspected before eval, Mikado might prove itself to be permeable to clever code injection attacks. Do not execute Mikado with super user privileges if you do not want to risk from such attacks, and always inspect third-party YAML scoring files before execution!